TVM stack is an end to end compilation stack to deploy deep learning workloads to all hardware backends. Thanks to the NNVM compiler support of TVM stack, we can now directly compile descriptions from deep learning frameworks and compile them to bare metal code. An impressive feature OF tvm is its ability to deploy computation workloads on different platforms, such as GPUs and mobile phones (will support more hardward backends).
However, when we want to test and profile cross compilation, it is hard to test different computation workloads on a heterogeneous device such as raspberry pi or a mobile phone. In order to optimize a computation task, one has to edit the code on the development PC, compile, deploy to the device, test, then modify the codes again to see whether it accelerates. The workflow looks like,
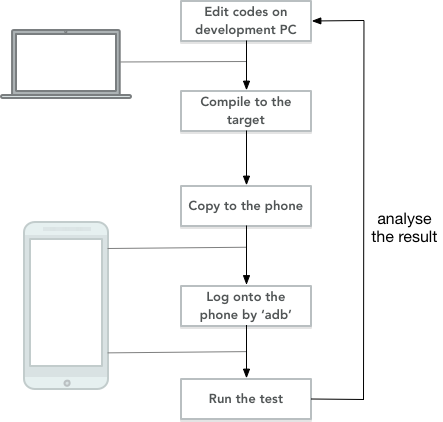
Is there any way to speed up this process?
Today we introduce an approach to deploy and test TVM workloads on Android Phones. We develop a TVM runtime for Java and build an Android APP upon it. The Android APP takes shared library as input and runs compiled functions on the mobile phone. Thus our workflow simplifies to,
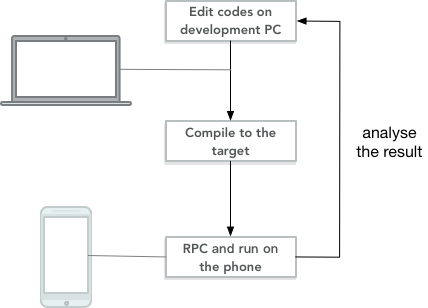
With the help of the TVM RPC, one can build TVM functions and NDArrays on a remote device. The ability to cross-compile to different platforms makes it easy to develop on one platform and test on another.
The process is illustrated as following:
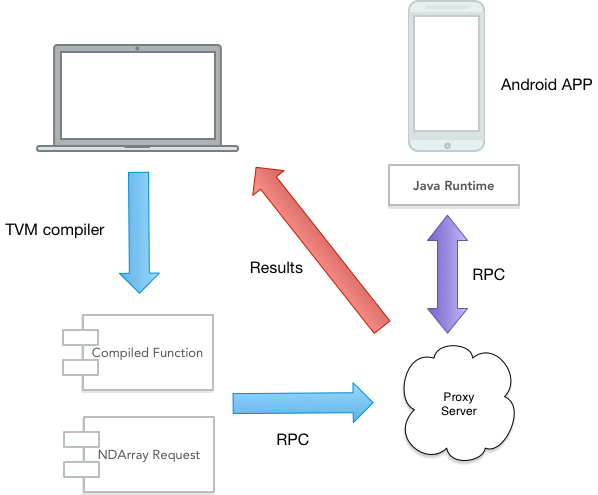
Run TVM APP on Android Phone
You can find Android RPC APP in apps/android_rpc. Please follow the instruction to build for your Android device. Once the APK is built, sign it using apps/android_rpc/dev_tools and install it on the phone. The APP looks like:
Usually we cannot start a standalone server on mobile phone, instead we start an proxy server and use our app to connect.
python -m tvm.exec.rpc_proxy
Create NDArray on the Phone
Now we can connect to the proxy server from the laptop:
from tvm.contrib import rpc
remote = rpc.connect("0.0.0.0", 9090, key="android")
This will give us a handler remote which we can use to communicate with the mobile phone. For instance, the following lines create a 1024x1024 matrix on phone’s GPU:
A = tvm.nd.array(
np.random.uniform(size=(1024, 1024)).astype(dtype),
ctx = remote.cl(0))
When A.asnumpy() is called from the laptop, the matrix A will be copied to phone’s RAM and then transfer to the laptop through the proxy server. The TVM RPC interface is transparent to users.
GEMM (Matrix Multiplication) on the Phone
Now we are going to introduce how to test matrix multiplication on an Android phone. First let’s define the very simple GEMM schedule:
import tvm
def gemm(N, bn):
A = tvm.placeholder((N, N), name='A')
B = tvm.placeholder((N, N), name='B')
k = tvm.reduce_axis((0, N), name='k')
C = tvm.compute(
(N, N),
lambda ii, jj: tvm.sum(A[ii, k] * B[k, jj], axis=k),
name='C')
s = tvm.create_schedule(C.op)
block_x = tvm.thread_axis("blockIdx.x")
thread_x = tvm.thread_axis("threadIdx.x")
bo, bi = s[C].split(C.op.axis[0], factor=bn)
to, ti = s[C].split(C.op.axis[1], factor=bn)
s[C].bind(bi, block_x)
s[C].bind(ti, thread_x)
print(tvm.lower(s, [A, B, C], simple_mode=True))
return tvm.build(s, [A, B, C],
"opencl",
target_host="llvm -target=arm64-linux-android",
name="gemm_gpu")
There’s nothing special except the last line. Here we set the target to ‘opencl’ since this is the computation language which our Mali GPU supports. Note that we set target_host to ‘llvm -target=arm64-linux-android’, it depends on what architecture your Android Phone is. We tested on Samsung Galaxy S6 Edge, which has a Mali-T760 GPU. Here is the CPU info for this phone,
$ adb shell
shell@zenltechn:/ $ cat /proc/cpuinfo
Processor : AArch64 Processor rev 2 (aarch64)
processor : 0
processor : 1
processor : 2
processor : 3
processor : 4
processor : 5
processor : 6
processor : 7
Features : fp asimd aes pmull sha1 sha2 crc32
CPU implementer : 0x41
CPU architecture: AArch64
CPU variant : 0x0
CPU part : 0xd03
CPU revision : 2
Hardware : SAMSUNG Exynos7420
Please refer to target triple to learn the compile options for LLVM.
We use tvm.contrib.ndk to build the shared library for the Android system,
from tvm.contrib import rpc, util, ndk
N = 1024
f = gemm(N, bn = 256)
temp = util.tempdir()
path_dso = temp.relpath("gemm_gpu.so")
f.export_library(path_dso, ndk.create_shared)
ndk.create_shared reads the environment variable TVM_NDK_CC to find the compiler & linker for the Android device. We can easily use NDK to generate standalone toolchain for our device. For example, the following commands generate standalone compilers and linkers for ARM64 Android devices.
cd /opt/android-ndk/build/tools/
./make-standalone-toolchain.sh --platform=android-24 --use-llvm --arch=arm64 --install-dir=/opt/android-toolchain-arm64
If everything goes right, we’ve got a shared library ‘gemm_gpu.so’. Now let’s upload it to the mobile phone, make the phone load the module and get a remote handler,
remote = rpc.connect("0.0.0.0", 9090, key="android")
remote.upload(path_dso)
f = remote.load_module("gemm_gpu.so")
Create the remote arrays and print the running time,
ctx = remote.cl(0)
import numpy as np
a_np = np.random.uniform(size=(N, N)).astype("float32")
b_np = np.random.uniform(size=(N, N)).astype("float32")
a = tvm.nd.array(a_np, ctx)
b = tvm.nd.array(b_np, ctx)
c = tvm.nd.array(np.zeros((N, N), dtype="float32"), ctx)
time_f = f.time_evaluator(f.entry_name, ctx, number=5)
cost = time_f(a, b, c).mean
print('%g secs/op, %g GFLOPS' % (cost, ngflops(N) / cost))
Now we can verify the results on PC,
np.testing.assert_almost_equal(
c.asnumpy(),
a_np.dot(b_np),
decimal=3)
In the case above, we develop and cross-compile to a binary file for our mobile phone. Through the proxy server, the binary is uploaded to the phone and run in its JVM. This approach makes it easy to develop and test different computation workloads on Android.
Java Runtime for TVM
The Android APP is built on top of the Java runtime, which provides minimum supports for TVM Function and NDArray. Here’s an example for registering function in tvm4j,
Function func = Function.convertFunc(new Function.Callback() {
@Override public Object invoke(TVMValue... args) {
StringBuilder res = new StringBuilder();
for (TVMValue arg : args) {
res.append(arg.asString());
}
return res.toString();
}
});
TVMValue res = func.pushArg("Hello").pushArg(" ").pushArg("World!").invoke();
assertEquals("Hello World!", res.asString());
res.release();
func.release();
As we have seen in the GEMM part, one can build shared library by Python and execute it by Java,
import ml.dmlc.tvm.Module;
import ml.dmlc.tvm.NDArray;
import ml.dmlc.tvm.TVMContext;
import java.io.File;
import java.util.Arrays;
public class LoadAddFunc {
public static void main(String[] args) {
String loadingDir = args[0];
Module fadd = Module.load(loadingDir + File.separator + "add_cpu.so");
TVMContext ctx = TVMContext.cpu();
long[] shape = new long[]{2};
NDArray arr = NDArray.empty(shape, ctx);
arr.copyFrom(new float[]{3f, 4f});
NDArray res = NDArray.empty(shape, ctx);
fadd.entryFunc().pushArg(arr).pushArg(arr).pushArg(res).invoke();
System.out.println(Arrays.toString(res.asFloatArray()));
arr.release();
res.release();
fadd.release();
}
}
Once you have built TVM library following the Installation Guide, run
make jvmpkg
make jvminstall
This will compile, package and install tvm4j in your local maven repository. Please refer to tvm4j for more information.
Remote Profile and Test on iPhone/iPad
Besides the Android RPC application, we also provide an iOS RPC app, through which we can easily profile and test TVM computation workloads on iPhone or iPad. It works almost the same as that on Android, while XCode and an iOS device are required.