Thierry Moreau(VTA architect), Tianqi Chen(TVM stack), Ziheng Jiang†(graph compilation), Luis Vega(cloud deployment)
Advisors: Luis Ceze, Carlos Guestrin, Arvind Krishnamurthy
Paul G. Allen School of Computer Science & Engineering, University of Washington
Hardware acceleration is an enabler for ubiquitous and efficient deep learning. With hardware accelerators appearing in the datacenter and edge devices, hardware specialization has taken on a prominent role in the deep learning system stack.
We are excited to announce the launch of the Versatile Tensor Accelerator (VTA, pronounced vita), an open, generic, and customizable deep learning accelerator design. VTA is a programmable accelerator that exposes a RISC-like programming abstraction to describe tensor-level operations. We designed VTA to expose the most salient and common characteristics of mainstream deep learning accelerators, such as tensor operations, DMA load/stores, and explicit compute/memory arbitration.
VTA is more than a standalone accelerator design: it’s an end-to-end solution that includes drivers, a JIT runtime, and an optimizing compiler stack based on TVM. The current release includes a behavioral hardware simulator, as well as the infrastructure to deploy VTA on low-cost FPGA hardware for fast prototyping. By extending the TVM stack with a customizable, and open source deep learning hardware accelerator design, we are exposing a transparent end-to-end deep learning stack from the high-level deep learning framework, down to the actual hardware design and implementation. This forms a truly end-to-end, hardware-software open source stack for deep learning systems.
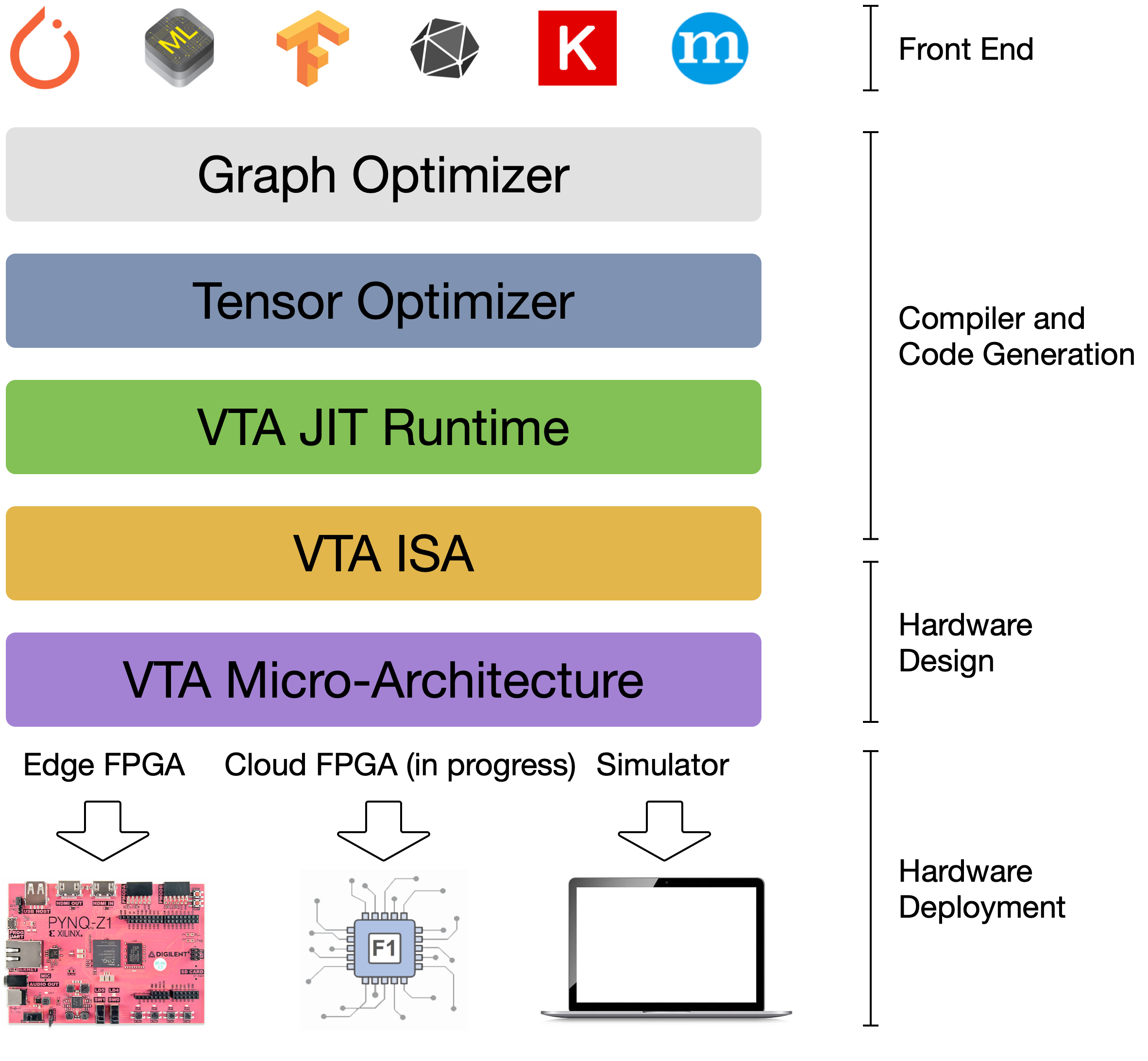
The VTA and TVM stack together constitute a blueprint for end-to-end, accelerator-centric deep learning system that can:
- Provide an open deep learning system stack for hardware, compilers, and systems researchers alike to incorporate optimizations and co-design techniques.
- Lower the barrier of entry for machine learning practitioners to experiment with novel network architectures, operators and data representations that require specialized hardware support.
Use-Case Scenarios for Researchers
We highlight ways in which the VTA design together with a complete TVM software stack can enable novel opportunities across hardware, compilers, and deep learning research.
Hardware Designers and Computer Architects
With new ASIC designs being regularly announced, providing a complete and usable software stack on top of novel hardware is essential to gain a competitive edge both in research circles, and commercially. Our VTA release provides a reference TVM software stack built for hardware accelerators. We hope to empower hardware designers to quickly build and deploy optimized deep learning libraries ready to be utilized by high-level frameworks of the likes of TensorFlow or PyTorch. Software support is essential for performing full-system evaluation to understand the limits and performance bottlenecks in hardware-accelerated systems. With the use of FPGAs as hardware deployment backends, we provide a complete solution for rapid and iterative hardware design prototyping. Finally, our vision is to see VTA grow into an collection of hardware designs, eventually leading to an open ecosystem of custom hardware accelerators.
In addition, VTA is one of the first hardware-software reproducible ACM artifacts, which can serve as a template for reproducible deep learning architecture research. The VTA artifact deployable using CK, was presented at ReQuEST 2018, co-located with ASPLOS.
Optimizing Compilers Researchers
Novel intermediate representations and optimizing compilers of the likes of TVM have been proposed to better take advantage of deep learning workloads characteristics. VTA complements TVM to provide accelerator-centric optimization passes, and low-level code generation. Our open-source deep learning compiler stack also aims to emulate the success of LLVM, by allowing the community to improve accelerator-centric compiler support over time, particularly as more hardware variants of VTA emerge. The extendability of the compiler stack, combined with the ability to modify the architecture and the programming interface of the hardware back-end should lead to exciting opportunities in hardware-software co-design for deep learning.
Deep Learning Researchers
A transparent and customizable software and hardware stack empowers deep learning researchers to come up with novel neural network operators, and data representations, all the while enabling the complete evaluation of those optimizations on end-to-end systems. Techniques like binarization are currently limited to CPU and GPU evaluations, unless significant engineering resources are dedicated to produce an FPGA or ASIC design that can evaluate the technique’s full energy savings potential. With a reference hardware stack that is readily deployable, VTA can lower the barrier of entry to hardware customization for machine learning practitioners who don’t possess much a hardware design background.
Technical Details
Stack Overview
The VTA deep learning accelerator and TVM stack can bridge the gap between productivity-oriented deep learning frameworks, and performance-focused hardware substrates, such as FPGAs.
- NNVM, the graph-level optimizer, provides a graph-level Intermediate Representation (IR) used as a common language between different deep learning frameworks to take advantage of graph-level optimizations, such as operator fusion. The NNVM IR is also used to specify data layout and data format constraints: e.g. tiling for tensorization, and bit-packing for ultra-low precision computing.
- TVM, the tensor-level optimizer, builds upon the Halide DSL and schedule primitives to provide an optimizing compiler capable of bringing performance portability for deep learning across hardware back-ends. TVM brings novel scheduling primitives that target specialized hardware accelerators, such as tensorization, which lowers computation onto specialized tensor-tensor hardware instructions. In addition, it provides schedule primitives and lowering rules that allow for explicit memory management to maximize resource utilization in hardware accelerators.
- The VTA runtime performs JIT compilation of VTA binaries (instruction streams and micro-kernel code), manages shared memory, and performs synchronization to hand off execution to VTA. The VTA runtime presents an API that looks generic to TVM, to hide complexities of platform-specific bookkeeping tasks. It exposes a C++ API that a TVM module can call into - this simplifies the future inclusion of other hardware accelerator designs, without having to drastically modify the upper TVM layers.
- VTA’s two-level ISA provides both (1) a high-level CISC ISA that describes variable latency operations such as DMA loads, or deep learning operators and (2) a low-level, and fixed latency RISC ISA that describe low-level matrix-matrix operations. This two-level ISA allows both code compactness, and expressiveness.
- Finally, VTA’s micro-architecture provides a flexible deep learning hardware design specification, that can be conveniently compiled onto other FPGA platforms, and eventually in the long term down to ASICs.
VTA Hardware Design Overview
The Vanilla Tensor Accelerator (VTA) is a generic deep learning accelerator built around a GEMM core, which performs dense matrix multiplication at a high computational throughput. The design is inspired by mainstream deep learning accelerators, of the likes of Google’s TPU accelerator. The design adopts decoupled access-execute to hide memory access latency and maximize utilization of compute resources. To a broader extent, VTA can serve as a template deep learning accelerator design, exposing a clean tensor computation abstraction to the compiler stack.
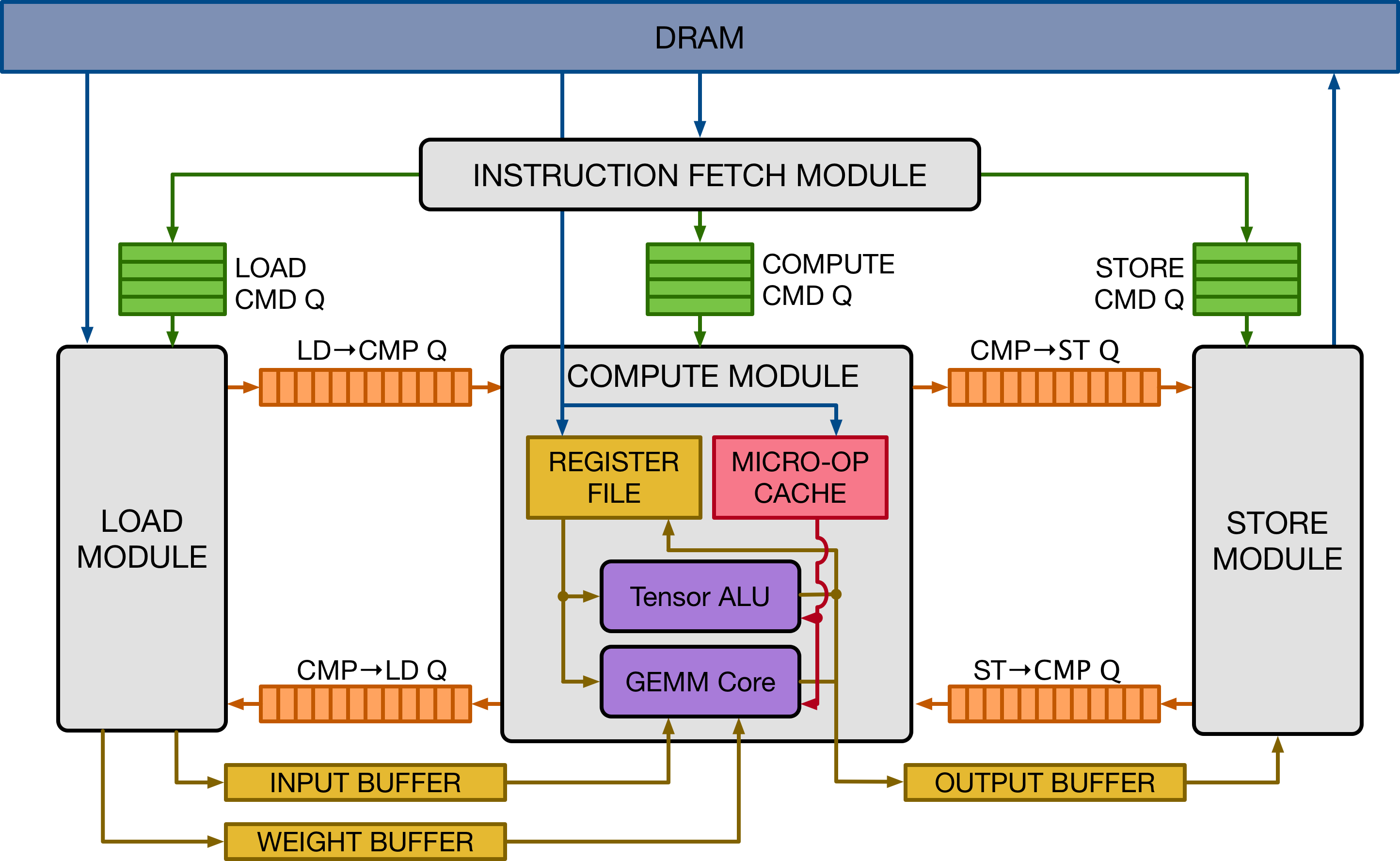
The figure above presents a high-level overview of the VTA hardware organization. VTA is composed of four modules that communicate between each other via FIFO queues and single-writer/single-reader SRAM memory blocks, to allow for task-level pipeline parallelism. The compute module performs both dense linear algebra computation with its GEMM core, and general computation with its tensor ALU. It operates on a register file which instead of storing scalar values, stores tensors of rank 1 or 2. The micro-op cache stores low-level code that dictates a sequence of operations to mutate the register file.
The VTA hardware design template offers modularity to the user, with the option to modify hardware datatypes, memory architecture, the GEMM core dimensions, hardware operators, and pipelining stages. Exposing multiple variants of VTA to the compiler stack facilitates the developments of compilers, since we can test TVM’s ability to target an multitude of hardware accelerators, rather than a single design.
VTA Prototyping with VTA Simulator and Pynq FPGA Board
The VTA release allows users to experiment with hardware acceleration, and accelerator-centric compiler optimizations in two ways. The first approach, which doesn’t require special hardware is to run deep learning workloads on a behavioral simulator of the VTA design. This simulator back-end is readily available for developers to experiment with. The second approach relies on an off-the-shelf and low-cost FPGA development board – the Pynq board, which exposes a reconfigurable FPGA fabric and an ARM SoC.
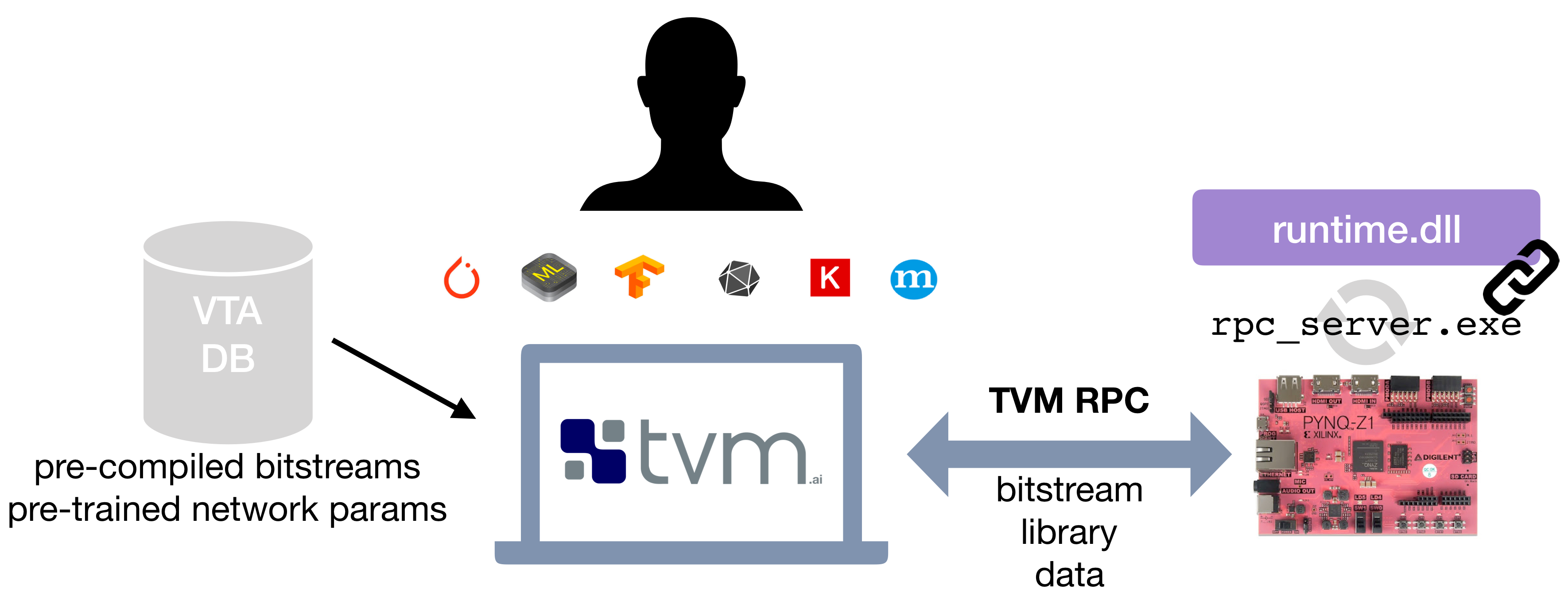
The VTA release offers a simple compilation and deployment flow of the VTA hardware design and TVM workloads on the Pynq platform, with the help of an RPC server interface. The RPC server handles FPGA reconfiguration tasks and TVM module invocation offloading onto the VTA runtime. The VTA runtime system runs on the ARM CPU of the Pynq embedded system, and generates VTA binaries on the fly to offload to the FPGA hardware. This complete solution allows for out-of-the-box prototyping on low-cost FPGAs, with an interactive and familiar Python environment, hiding much of the complexity and headaches of FPGA design away from the user.
For programmers familiar with hardware and FPGAs, we expose the VTA design expressed in HLS C, and provide scripts built on top of the Xilinx toolchains to compile the design into an FPGA bitstream. We are currently building a repository of VTA variants, so that users can explore different design variants for their deep learning workloads without having to go through the time consuming FPGA compilation process.
Performance Assessment
VTA is at its early stages of development and we expect more performance improvements and optimizations to come. As of now we offer end-to-end performance evaluations on the low-cost Pynq board which incorporates a dated 28nm FPGA fabric. While this platform is meant for prototyping (the 2012 FPGA cannot compete with modern ASICs), we are porting VTA to newer high-performance FPGA platforms that will offer more competitive performance.
We are working on more experiments and will release new results as they are obtained.
Resource Utilization on ResNet-18
A popular method used to assess the efficient use of hardware are roofline diagrams: given a hardware design, how efficiently are different workloads utilizing the hardware compute and memory resources. The roofline plot below shows the throughput achieved on different convolution layers of the ResNet-18 inference benchmark. Each layer has a different arithmetic intensity, i.e. compute to data movement ratio. In the left half, convolution layers are bandwidth limited, whereas on the right half, they are compute limited.
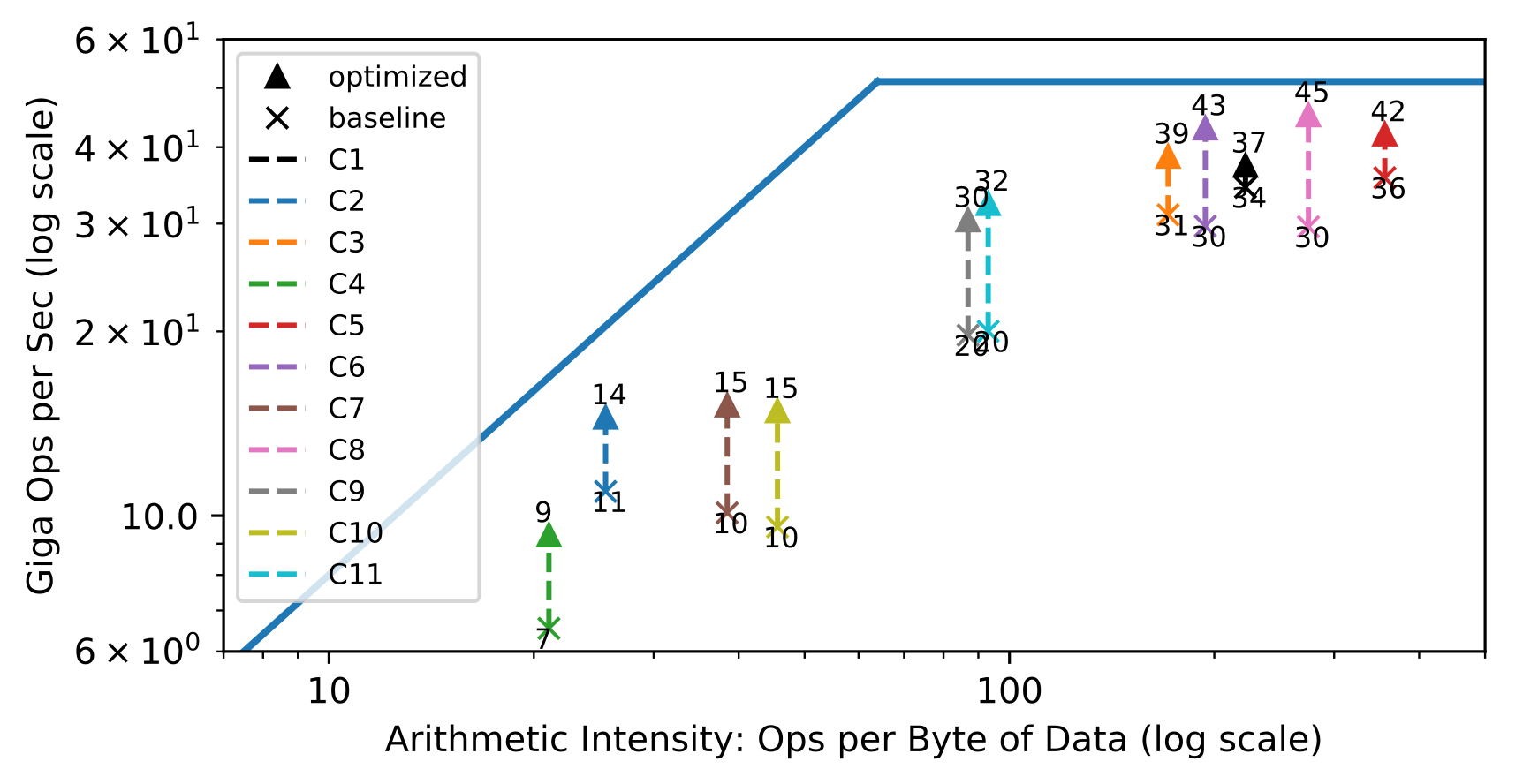
The goal behind designing a hardware architecture, and a compiler stack is to bring each workload as close as possible to the roofline of the target hardware. The roofline plot shows the effects of having the hardware and compiler work together to maximize utilization of the available hardware resources. The technique showcased is latency hiding, which requires explicit dependence tracking at the hardware level, compiler support to partition work, explicit dependence insertion in the instruction stream during code-generation. The result is an overall higher utilization of the available compute and memory resources.
End to end ResNet-18 evaluation
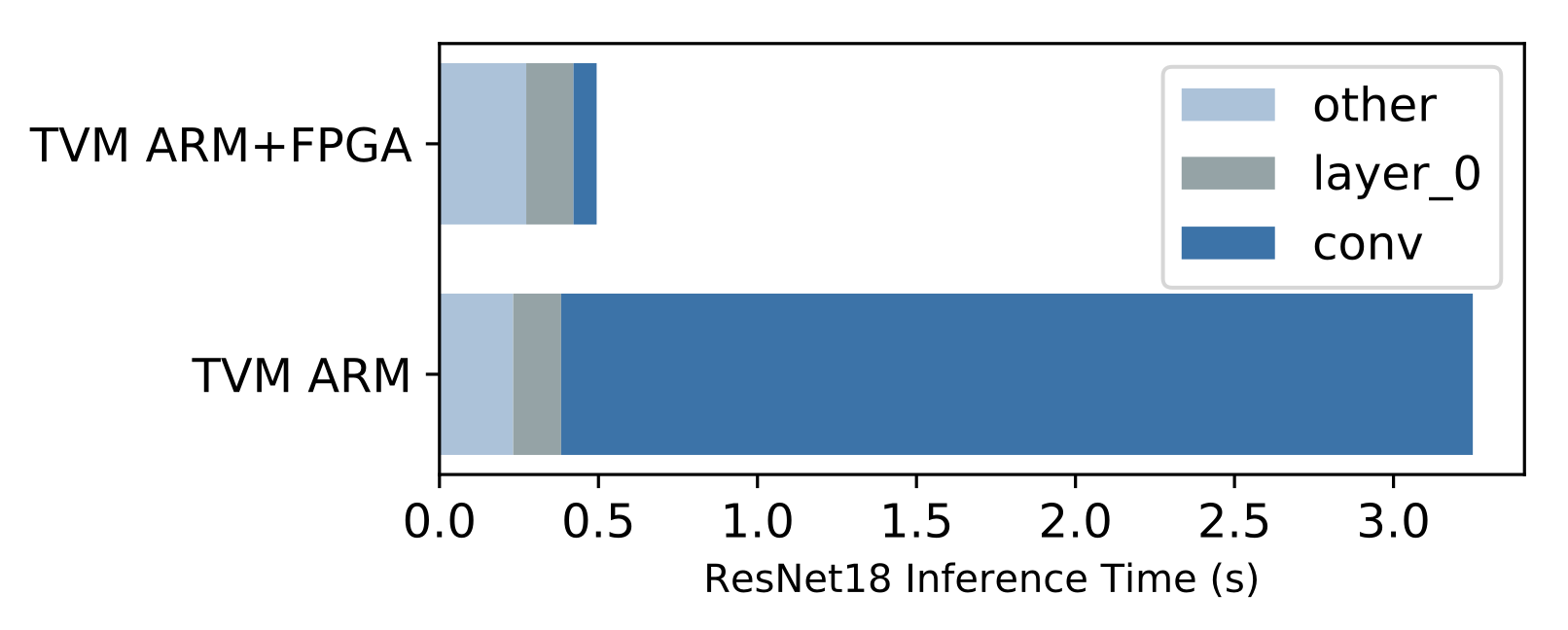
A benefit of having a complete compiler stack built for VTA is the ability to run end-to-end workloads. This is compelling in the context of hardware acceleration because we need to understand what performance bottlenecks, and Amdahl limitations stand in the way to obtaining faster performance. The bar plot above shows inference performance with and without offloading the ResNet convolutional layers to the FPGA-based VTA design, on the Pynq board’s ARM Cortex A9 SoC. At a glance, it iss clear that VTA accomplishing its goal, reducing the time it takes to perform convolutions on the CPU (dark blue). However, it becomes apparent that other operators need offloading, as they now constitute a new bottleneck. This kind of high-level visibility is essential to system designers who want to understand how systems affect end-to-end performance.
Open Source Effort
VTA is research effort at the Paul G. Allen School Computer Science and Engineering at University of Washington, and is now integrated into the TVM stack. The TVM project follows the Apache open-source model, to create a community maintained project. You are more than welcome to join us and lead the effort.
Acknowledgements
VTA is a research project that came out of the SAML group, which is generously supported by grants from DARPA and the National Science Foundation and gifts from Huawei, Oracle, Intel and anonymous donors.
Get Started!
- TVM and VTA Github page can be found here: https://github.com/dmlc/tvm.
- You can get started with easy to follow tutorials on programming VTA with TVM.
- For more technical details on VTA, read our VTA technical report on ArXiv.