There is an increasing need to bring machine learning to a wide diversity of hardware devices. Current frameworks rely on vendor-specific operator libraries and optimize for a narrow range of server-class GPUs. Deploying workloads to new platforms – such as mobile phones, embedded devices, and accelerators (e.g., FPGAs, ASICs) – requires significant manual effort.
TVM is an open source deep learning compiler stack that closes the gap between the productivity-focused deep learning frameworks, and the performance- or efficiency-oriented hardware backends. Today, we are glad to announce that the TVM community has decided to move on to Apache incubator, and becomes an Apache(incubating) project.
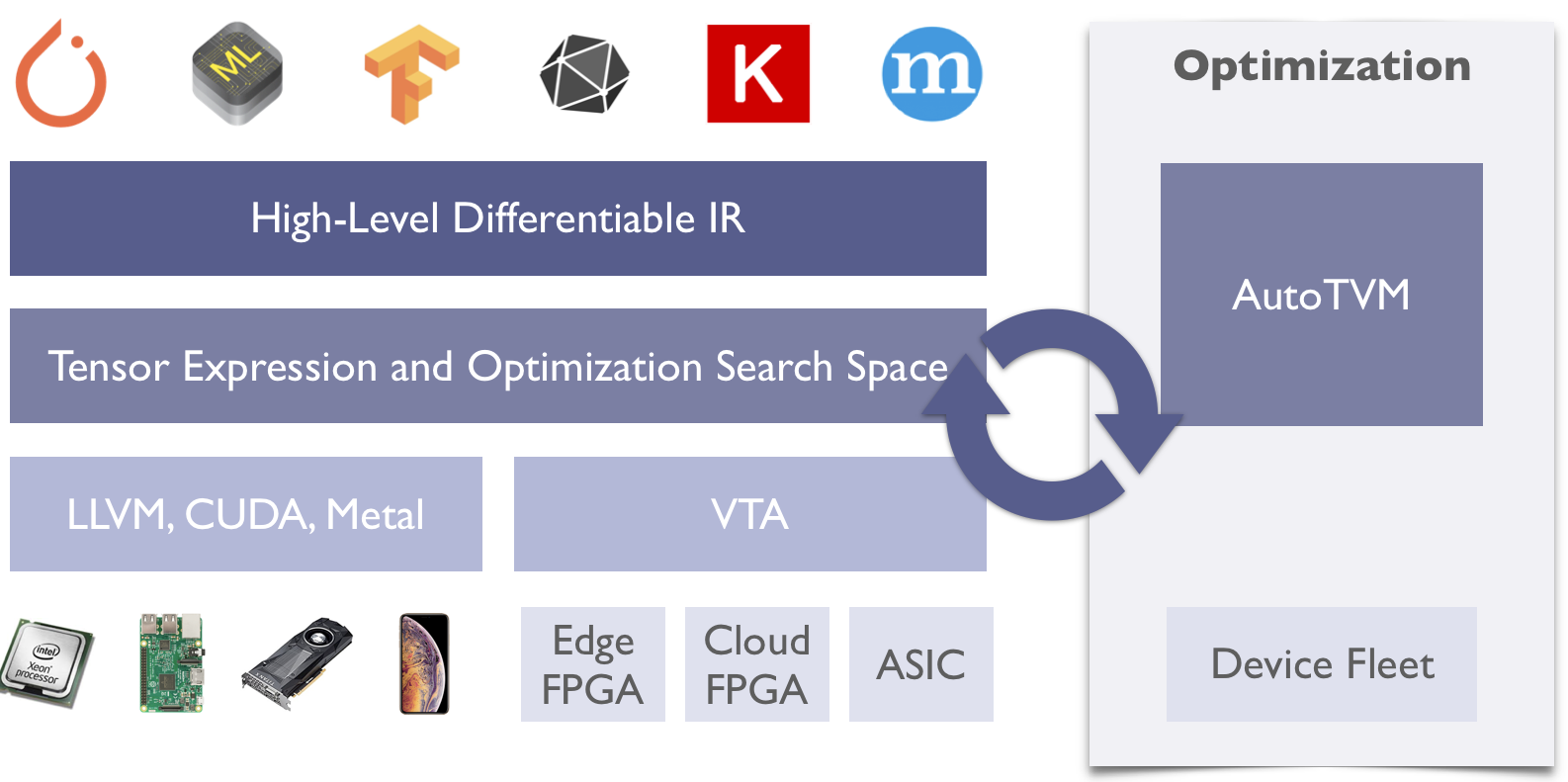
TVM stack began as a research project at the SAMPL group of Paul G. Allen School of Computer Science & Engineering, University of Washington. The project uses the loop-level IR and several optimizations from the Halide project, in addition to a full deep learning compiler stack to support machine learning workloads for diverse hardware backends.
Since its introduction, the project was driven by an open source community involving multiple industry and academic institutions. Currently, the TVM stack includes a high-level differentiable programming IR for high-level optimization, a machine learning driven program optimizer and VTA – a fully open sourced deep learning accelerator. The community brings innovations from machine learning, compiler systems, programming languages, and computer architecture to build a full-stack open source deep learning compiler system. The project has been used in production in several major companies.
Besides the technical innovations, the community adopts an open, welcoming and neutral policy. The project is run by committers who are elected purely based on their merit of the contributions to the project. Besides the contributors from UW SAMPL, the community now has nearly 200 contributors that come from Amazon Web Services (AWS), Qualcomm, Facebook, Google, Huawei, AMD, Microsoft, Cornell University, University of California, Berkeley, and more. The community successfully organized the first developer conference last December which attracted more than 180 attendees from all around the world. Moving forward to the Apache, we will continue to exercise this principle in an effort to bring deep learning compilation to everyone.
We would like to take this chance to thank the Allen School for supporting the SAMPL team that gave birth to the TVM project. We would also like to thank the Halide project which provided the basis for TVM’s loop-level IR and initial code generation. We would like to thank our Apache incubator mentors for introducing the project to Apache and providing useful guidance. Finally, we would like to thank the TVM community and all of the organizations, as listed above, that supported the developers of TVM.
See also the Allen School news about the transition here, TVM conference program slides and recordings, and our community guideline here. Follow us on Twitter: @ApacheTVM.