TLDR
We introduced support for WASM and WebGPU to the Apache TVM deep learning compiler. Our experiments shows that TVM’s WebGPU backend can get close to native GPU performance when deploying models to the web.
Introduction
Computing is one of the pillars of modern machine learning applications. The introduction of the GPU to accelerate deep learning workloads has increased the rate of progress dramatically. Given the growing requirement to deploy machine learning everywhere, the browser becomes a natural place to deploy intelligent applications.
While TensorFlow.js and ONNX.js are existing efforts to bring machine learning to the browser, there still exist non-trivial gaps in performance between the web versions and native ones. One of the many reasons is the lack of standard and performant access to the GPU on the web. WebGL lacks important features such as compute shaders and generic storage buffers that are necessary for high performance deep learning.
WebGPU is the upcoming standard for next generation web graphics which has the possibility to dramatically change this situation. Like the latest generation graphics APIs such as Vulkan and Metal, WebGPU offers first-class compute shader support.
To explore the potential of using WebGPU for machine learning deployment in the browser, we enhanced the deep learning compiler Apache(incubating) TVM to target WASM (for host code that computes the launching parameters and calls into the device launch) and WebGPU (for device execution). Our preliminary results are quite positive — for the first time, we can deploy machine learning applications on the web while still getting near native performance on the GPU.
Machine Learning Compiler
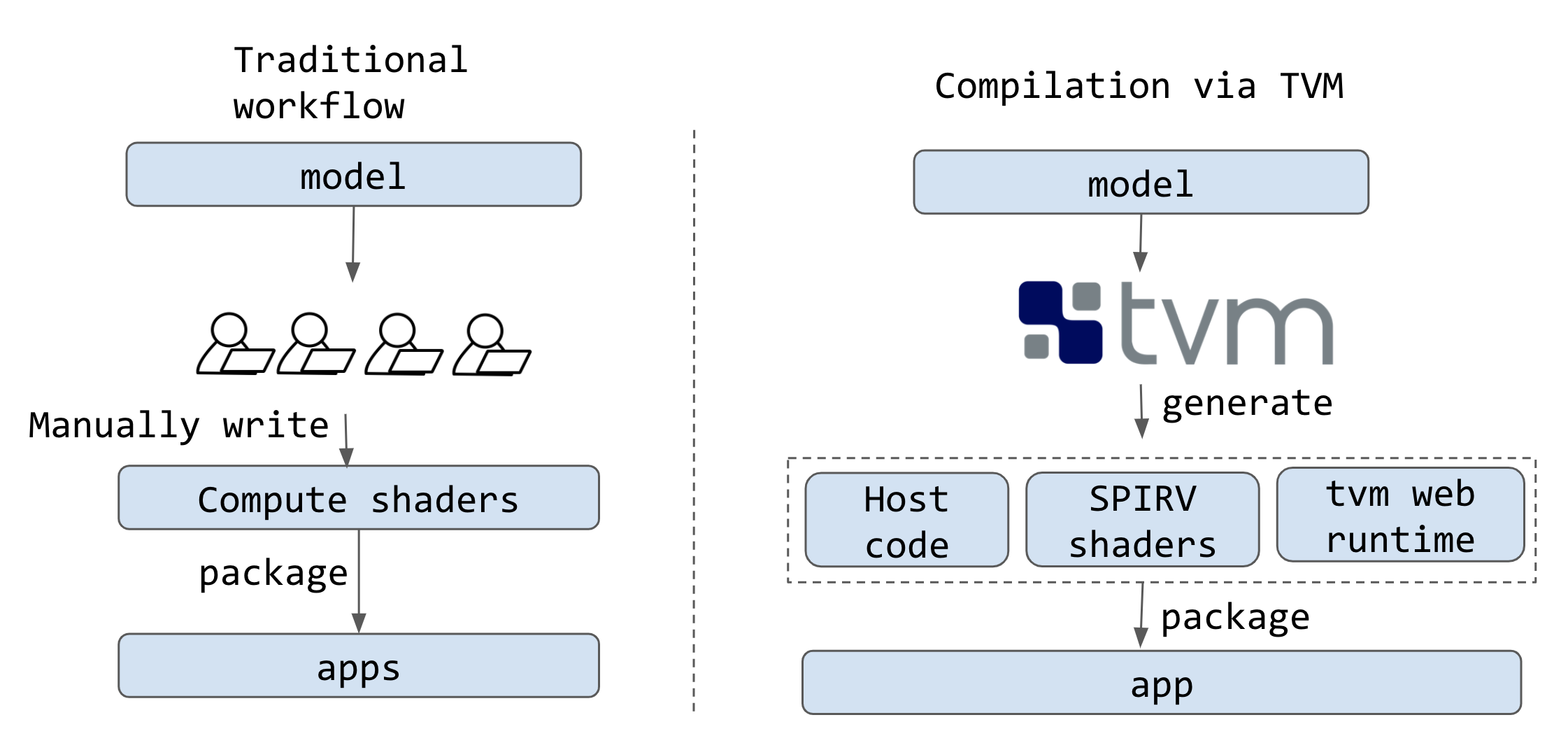
One natural reaction when trying out WebGPU is to write shaders for primitive operators in deep neural networks (matrix multiplication and convolution) and then directly optimize their performance. This is the traditional workflow used by existing frameworks such as TensorFlow.js.
Instead, we apply a compilation based approach. TVM automatically ingests models from high-level frameworks such as TensorFlow, Keras, PyTorch, MXNet and ONNX and uses a machine learning driven approach to automatically generate low level code, in this case compute shaders in SPIR-V format. The generated code can then be packaged as a deployable module.
One important advantage of the compilation based approach is the reuse of infrastructure. We are able to effortlessly (relative to other approaches) target the web by reusing the infrastructure for optimizing GPU kernels for native platforms such as CUDA, Metal and OpenCL. If the mapping of the WebGPU API to native APIs is efficient we can expect similar performance with very little work. More importantly, the AutoTVM infrastructure allows us to specialize the compute shaders for specific models, enabling the generation of the best compute shaders for our specific model of interest.
Building a WASM and WebGPU Compiler
In order to build a compiler that can target WASM and WebGPU, we need the following elements:
- A SPIR-V generator for compute shaders.
- A WASM generator for the host program.
- A runtime to load and execute the generated program.
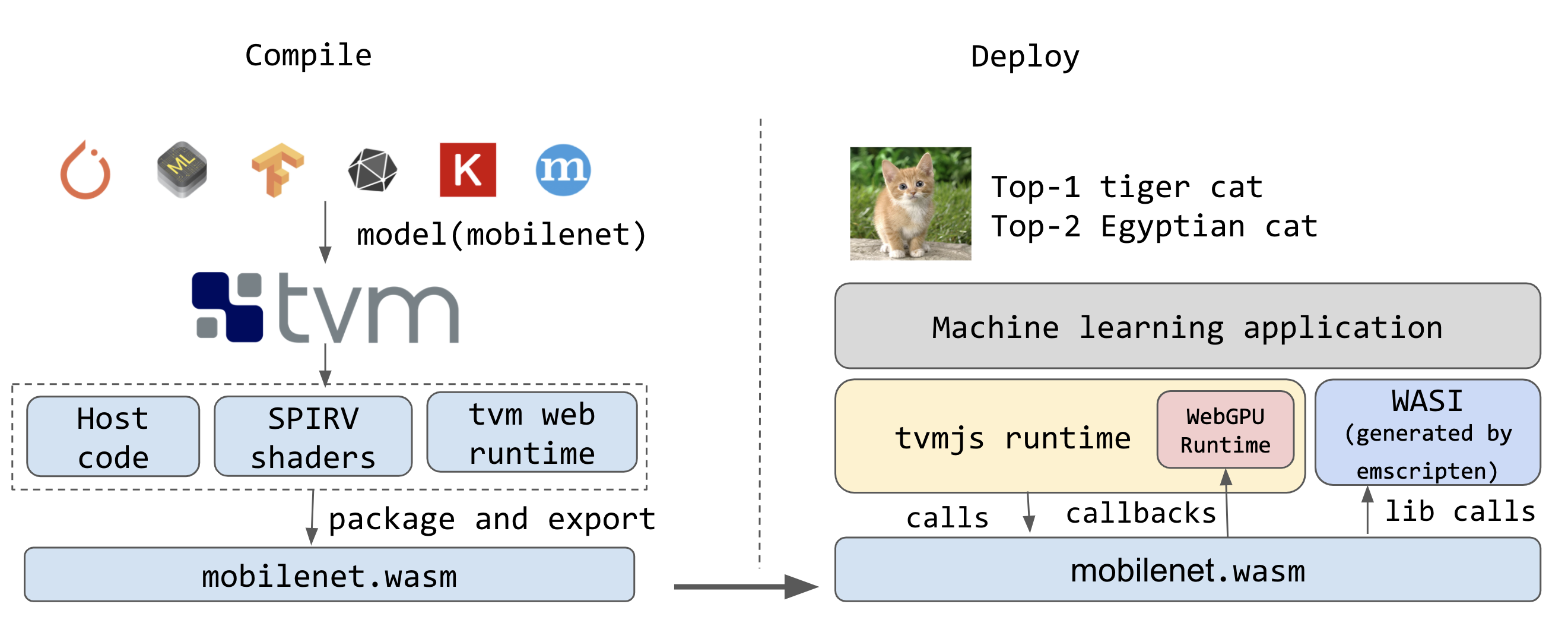
Luckily, TVM already has a SPIR-V target for Vulkan, and uses LLVM for host code generation. So we can just repurpose the two to generate the device and host programs.
The main challenge is the runtime. We need a runtime to load the shader code, and to enable the host code talk to communicate with the shader correctly. TVM has a minimum C++ based runtime. We build a minimum web runtime library and link it with the generated shader and host driving code, producing a single WASM file. However, this WASM module still contains two unknown dependencies:
- The runtime needs to call into system library calls (malloc, stderr).
- The wasm runtime needs to interact with the WebGPU driver (in javascript where the WebGPU API is the first-class citizen).
WASI is a standard solution to solve the first problem. While there is not yet a mature WASI on the web, we can use emscripten to generate a WASI-like library (see discussion here) to provide these system libraries.
We solve the second problem by building a WebGPU runtime inside TVM’s JS runtime, and calling back to these functions from the WASM module when invoking GPU code. Using the PackedFunc mechanism in TVM’s runtime system, we can directly expose high-level runtime primitives by passing JavaScript closures to the WASM interface. This approach keeps most of the runtime code in JavaScript, we could bring more JS code into the WASM runtime as WASI and WASM support matures.
Performance
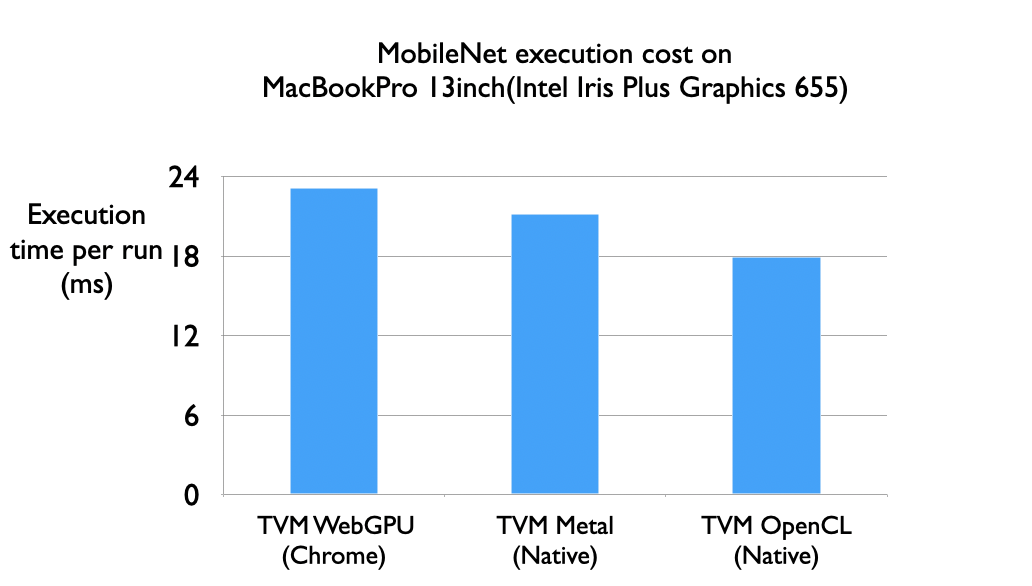
We ran a quick experiment comparing the execution of a full computational graph via TVM’s WebGPU backend and native targets that use native GPU runtimes (Metal and OpenCL). On the MobileNet model, we can find that the WebGPU can get close to matching the performance of Metal. Assuming Chrome WebGPU’s runtime targets Metal instead of OpenCL on the MacOS, we can safely assume there is little to no performance loss when targeting the GPU.
This benchmark excludes the CPU to GPU data copy cost and only benchmarks the GPU execution. Currently the data copy from CPU to GPU can still take 25% of the execution time; however, these costs can further be amortized via approaches like double buffering in a continuous execution setting.
Our reported end-to-end running time of mobilenet is by no means optimal, since we simply reused a tuned programs from GTX 1080 Ti, which is very different from the Intel graphics GPU. We expect further performance boost by using AutoTVM on the target platform of interest.
Looking to the Future
Our results suggest many interesting opportunities for machine learning on the web. Notably, WebGPU is an API that is still evolving and its implications could go beyond web applications. For example one could target native APIs of WebGPU as it matures and becomes standardized through WASI, enabling standalone WASM applications that make use of WebGPU.
The TVM community is also actively working on a Rust based runtime that would enable much more robust WASM support and enable easier interaction with projects like wgpu, and the Rust WASM ecosystem. As an open source project, we are looking for contributors who can bring in new ideas and help push the project in these exciting directions.
The proposed approach provides effective machine learning support for most WASM’s application scenarios. The close to native performance could unlock better federated learning capabilities on the browser. The same compiled package should also be able to run on native WASM executors to provide sandbox for the applications.
Show me the Code
Acknowledgement
We would like to thank the emscripten project for providing the WASM compilation infrastructures as well as the JS library support on the web. We would also like to thank the WebGPU community for various helpful discussions. Thanks to Fletcher Haynes for valuable feedbacks to the post.