Introducing TVM Auto-scheduler (a.k.a. Ansor)
Optimizing the execution speed of deep neural networks is extremely hard with the growing model size, operator diversity, and hardware heterogeneity. From a computational perspective, deep neural networks are just layers and layers of tensor computations. These tensor computations, such as matmul and conv2d, can be easily described by mathematical expressions. However, providing high-performance implementations for them on modern hardware can be very challenging. We have to apply various low-level optimizations and utilize special hardware intrinsics to achieve high performance. It takes huge engineering effort to build linear algebra and neural network acceleration libraries like CuBLAS, CuDNN, oneMKL, and oneDNN.
Our life will be much easier if we can just write mathematical expressions and have something magically turn them into efficient code implementations. Three years ago, deep learning compiler TVM and its search module AutoTVM were built as the first step towards this goal. AutoTVM employs a template-based search algorithm to find efficient implementations for a given tensor computation. However, it is a template-based approach, so it still requires domain experts to implement a non-trivial manual template for every operator on every platform. Today, there are more than 15k lines of code for these templates in the TVM code repository. Besides being very hard to develop, these templates often have inefficient and limited search spaces, making them unable to achieve optimal performance.
To address the limitations of AutoTVM, we started project Ansor aiming at a fully automated auto-scheduler for generating code for tensor computations. Ansor auto-scheduler only takes tensor expressions as input and generates high-performance code without manual templates. We made innovations in the search space construction and search algorithm. As a result, the auto-scheduler can achieve better performance with less search time in a more automated way.
Ansor auto-scheduler is now integrated into Apache TVM as tvm.auto_scheduler package.
This is a joint effort by collaborators from UC Berkeley, Alibaba, AWS and OctoML.
Detailed tutorials are available for Intel CPUs, ARM CPUs, NVIDIA GPUs, and Mali GPUs on the TVM website [1].
In this blog post, we will give a high-level introduction and show some benchmark results.
System Overview
AutoTVM vs Auto-scheduler

Table 1 compares the workflow for generating code for an operator in AutoTVM and auto-scheduler. In AutoTVM, the developer has to go through three steps. In step 1, the developer has to write the compute definition in TVM’s tensor expression language. This part is relatively easy because TVM’s tensor expression language looks just like math expressions. In step 2, the developer has to write a schedule template, which typically consists of 20-100 lines of tricky DSL code. This part requires domain expertise of both the target hardware architecture and operator semantics, so it is difficult. The last step, step 3, is automated by a search algorithm.
In auto-scheduler, we eliminate the most difficult step 2 by automatic search space construction and accelerate step 3 with a better search algorithm. By doing automatic search space construction, we not only eliminate huge manual effort, but also enabling the exploration of much more optimization combinations. This automation does not come for free, because we still need to design rules to generate the search space. However, these rules are very general. They are based on static analysis of the tensor expressions. We only need to design a few general rules once and can apply them to almost all tensor computations in deep learning.
Search Process
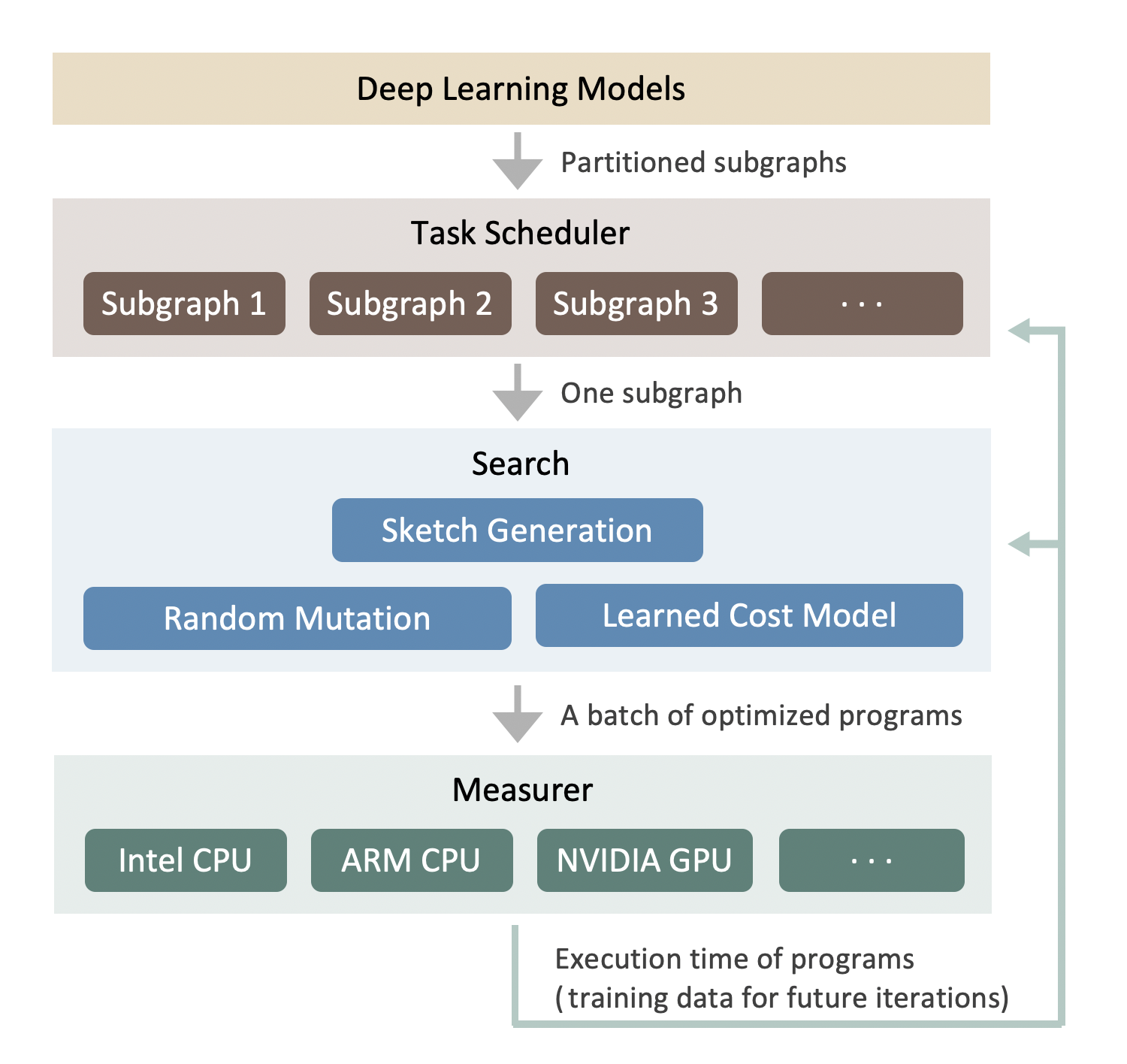
Figure 1. shows the search process of auto-scheduler when optimizing a whole neural network. The system takes deep learning models as input. It then partitions the big model into small subgraphs with Relay’s operator fusion pass. A task scheduler is utilized to allocate the time resource for optimizing many subgraphs. At each iteration, it picks a subgraph that has the most potential to increase the end-to-end performance. For this subgraph, we analyze its tensor expression and generate several sketches for it. Then we run evolutionary search with a learned cost model to get a batch of optimized programs. The optimized programs are sent to actual hardware for measurements. When the measurements are finished, the profiling results are used as feedback to update all components of the system. This process is repeated iteratively until the optimization converges or we run out of time budget. More technical details can be found in our paper [3] and our code.
It is worth notiing that since the auto-scheduler generates schedules from scratch, it reuses the existing computation definitions in TOPI but not schedule templates.
Benchmark Results
In this section, we benchmark the performance of AutoTVM and Auto-scheduler. The CPU benchmark is done on an AWS c5.9xlarge, which is equipped with an Intel 18-core skylake 8124-m CPU. The GPU benchmark is done on an AWS g4dn.4xlarge, which is equipped with an NVIDIA T4 GPU. All benchmark code, raw data, tuning logs can be found in this repo [2].
Performance of the generated code
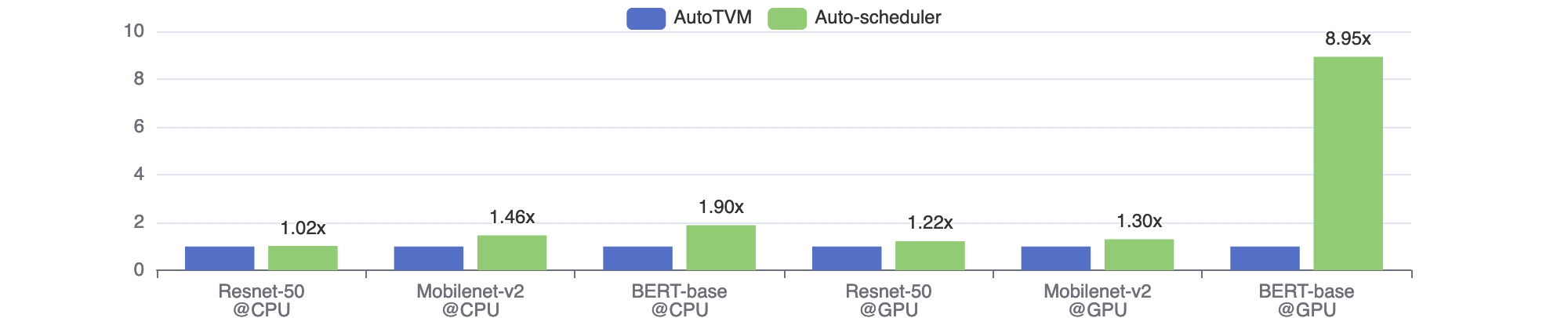
We benchmark the fp32 single-batch inference latency on three networks. Figure 2 shows the relative speedup of auto-scheduler against AutoTVM. We can see auto-scheduler outperforms AutoTVM in all cases with 1.02x to 8.95x speedup. This is because auto-scheduler explores a larger search space, which covers more efficient combinations of optimizations that are missed in TOPI manual templates. The BERT-base@GPU is an extreme case where the manual templates are very badly designed. In other words, the manual template for dense layers does not perform well for the shapes in BERT model.
Search Time
As we know, the search-based approaches can be very time-consuming, so we also care about the search time. It typically takes several hours to let the search converge for a single neural network. Figure 3 compares the search time of AutoTVM and auto-scheduler. Auto-scheduler requires much less time to converge in most cases, despite its larger search space. This is mainly because of auto-scheduler has a better cost model and task scheduler.

More Results
The repo above serves as an internal benchmark tool for TVM, so it only compares the latest AutoTVM and AutoScheduler. You can find results for more libraries and backends in our paper [3]. Recently, this blog post [4] also tried auto-scheduler on an Apple M1 chip and got some good results.
Conclusion
We build TVM auto-scheduler, a system that automatically generates high-performance code for tensor expressions. Compared with the predecessor AutoTVM, auto-scheduler does not require manual templates. Besides, auto-scheduler is capable of generating schedules with better performance in a shorter time. We achieve this by making innovations in the search space construction and search algorithm.
We are excited about the current performance of auto-scheduler. In the future, we are interested in extending the ability of auto-scheduler to support sparse operators, low-precision operators, and dynamic shape better.
Links
[1] Tutorials: https://tvm.apache.org/docs/tutorials/index.html#autoscheduler-template-free-auto-scheduling
[2] Benchmark repo: https://github.com/tlc-pack/TLCBench
[3] OSDI Paper: Ansor : Generating High-Performance Tensor Programs for Deep Learning
[4] Results on Apple M1 chip: https://medium.com/octoml/on-the-apple-m1-beating-apples-core-ml-4-with-30-model-performance-improvements-9d94af7d1b2d.