Now TVM comes with a brand-new OpenGL/WebGL backend! This blog post explains what it is, and what you can achieve with it.
The OpenGL/WebGL Backend
TVM already targets a lot of backends covering a variety of platforms: CPU, GPU, mobile devices, etc… This time we are adding another backend: OpenGL/WebGL.
OpenGL/WebGL enables us to leverage the GPU on an environment which does not have CUDA installed. It is, for the time being, the only way of using the GPU inside a browser.
This new backend allows us to use OpenGL/WebGL in 3 different ways:
- Local OpenGL: We can compile a deep learning model into OpenGL and directly run it on the local machine, entirely using Python.
- WebGL with RPC: We can compile a deep learning model into WebGL and export it as a shared library via Emscripten, with JavaScript host code and WebGL device code. Then we can deploy that library through RPC onto a TVM JavaScript runtime system running inside a browser.
- WebGL with static library: We can compile a deep learning model into WebGL, link it with the TVM JavaScript runtime system and export the entire package. Then we can run the model in a web page on a browser, with no dependency. The detailed flow is described in figure 1.
We rely on Emscripten and its fastcomp LLVM backend to generate the javascript backend.
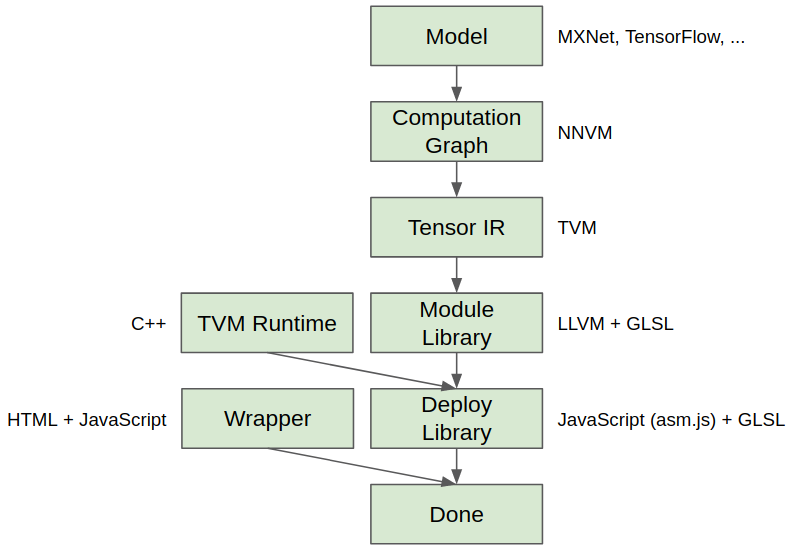
Figure 1
See here for examples of all three of them.
How is this Different from X?
Running a neural network on a browser isn’t an entirely new thing. Andrej Karpathy’s ConvNetJS and Google’s DeepLearning.JS are examples of that.
So what’s unique about TVM with WebGL? The big difference is that the op kernels in TVM are automatically compiled, not handwritten. As shown in Figure 2, TVM utilizes a unified AST to define kernels, and compiles it to code on different platforms.

Figure 2
This means that:
- To deploy your existing model to WebGL, you don’t need to write a lot of additional code. The NNVM/TVM model definition is the same for all targets, so you just need to compile it to a new target.
- To add a new op kernel, you only need to define it in TVM once, instead of implementing it once for every target. You don’t need to know how to write GLSL code to add a new op kernel to WebGL!
Benchmark
Here we perform a benchmark for a typical workload: image classification using resnet18.
I’m using my 5-year-old laptop which has an 8-core Intel® Core™ i7-3610QM, and a GTX650M.
In this benchmark, we download a resnet18 model from the Gluon model zoo, and perform end-to-end classification on a cat image. We only measure the model execution time (without model/input/parameter loading), and each model is run 100 times to get an average. The results are shown in figure 3.
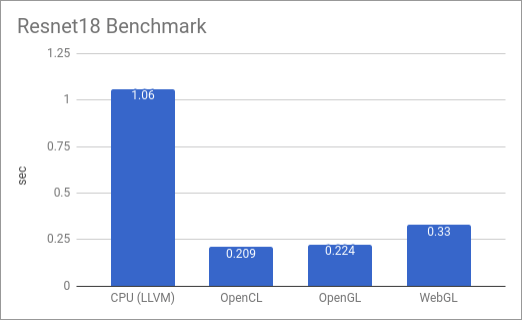
Figure 3
The benchmark is run in 4 different settings:
- CPU (LLVM): The model is compiled into LLVM IR and JIT’ed. Therefore, it is run entirely on the CPU.
- OpenCL: The model is compiled into OpenCL. There is still some glue code compiled to LLVM, which is responsible for setting up and launching OpenCL kernels. Then we run it on the local machine.
- OpenGL: Same as OpenCL, but compiled to OpenGL.
- WebGL: The glue code is compiled to LLVM, and transformed to JavaScript using Emscripten’s Fastcomp LLVM backend. The device code is compiled to WebGL. We execute the model in Firefox.
From the result above we can observe that, the TVM OpenGL backend has a similar performance as OpenCL. More interestingly, the WebGL version inside the browser isn’t significantly slower than desktop OpenGL. Considering that the host code is JavaScript, this is quite surprising. This might be due to the fact that Emscripten generates asm.js which enables dramatic optimizations in Firefox.
This is a first step toward automatic compilation of deep learning models into web browser. We expect more performance improvements as we bring optimizations into the TVM stack.
Show me the Code
- Checkout this complete code example.
Acknowledgement
We thank the developers of Emscripten for providing the fastcomp toolchain and the helps during the development.